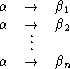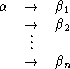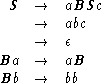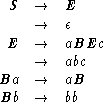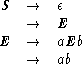ááááááLanguages
ááááááGrammars
ááááááDerivations
ááááááDerivation Graphs
ááááááLeftmost Derivations
ááááááHierarchy of Grammars
The universe of strings is a useful medium for the representation of information as
long as there exists a function that provides the interpretation for the information carried
by the strings. An interpretation is just the inverse of the mapping that a representation
provides, that is, an interpretation is a function g from ![]() * to D for some alphabet
* to D for some alphabet ![]() and some set D. The string 111, for instance, can be interpreted as the number
one hundred and eleven represented by a decimal string, as the number seven
represented by a binary string, and as the number three represented by a unary
string.
and some set D. The string 111, for instance, can be interpreted as the number
one hundred and eleven represented by a decimal string, as the number seven
represented by a binary string, and as the number three represented by a unary
string.
The parties communicating a piece of information do the representing and interpreting. The representation is provided by the sender, and the interpretation is provided by the receiver. The process is the same no matter whether the parties are human beings or programs. Consequently, from the point of view of the parties involved, a language can be just a collection of strings because the parties embed the representation and interpretation functions in themselves.
In general, if ![]() is an alphabet and L is a subset of
is an alphabet and L is a subset of ![]() *, then L is said to be a language
over
*, then L is said to be a language
over ![]() , or simply a language if
, or simply a language if ![]() is understood. Each element of L is said to be a sentence
or a word or a string of the language.
is understood. Each element of L is said to be a sentence
or a word or a string of the language.
Exampleá1.2.1 áá
{0, 11, 001}, {![]() , 10}, and {0, 1}* are subsets of {0, 1}*, and so they are languages over
the alphabet {0, 1}.
, 10}, and {0, 1}* are subsets of {0, 1}*, and so they are languages over
the alphabet {0, 1}.
The empty set Ï and the set {![]() } are languages over every alphabet. Ï is a language that
contains no string. {
} are languages over every alphabet. Ï is a language that
contains no string. {![]() } is a language that contains just the empty string.
} is a language that contains just the empty string. ![]()
The union of two languages L1 and L2, denoted L1 ![]() L2, refers to the language that
consists of all the strings that are either in L1 or in L2, that is, to { x | x is in L1
or x is in L2 }. The intersection of L1 and L2, denoted L1
L2, refers to the language that
consists of all the strings that are either in L1 or in L2, that is, to { x | x is in L1
or x is in L2 }. The intersection of L1 and L2, denoted L1 ![]() L2, refers to the
language that consists of all the strings that are both in L1 and L2, that is, to { x | x
is in L1 and in L2 }. The complementation of a language L over
L2, refers to the
language that consists of all the strings that are both in L1 and L2, that is, to { x | x
is in L1 and in L2 }. The complementation of a language L over ![]() , or just the
complementation of L when
, or just the
complementation of L when ![]() is understood, denoted
is understood, denoted ![]() , refers to the language that
consists of all the strings over
, refers to the language that
consists of all the strings over ![]() that are not in L, that is, to { x | x is in
that are not in L, that is, to { x | x is in ![]() * but not in
L }.
* but not in
L }.
Exampleá1.2.2 áá
Consider the languages L1 = {![]() , 0, 1} and L2 = {
, 0, 1} and L2 = {![]() , 01, 11}. The union of these
languages is L1
, 01, 11}. The union of these
languages is L1 ![]() L2 = {
L2 = {![]() , 0, 1, 01, 11}, their intersection is L1
, 0, 1, 01, 11}, their intersection is L1 ![]() L2 = {
L2 = {![]() }, and the
complementation of L1 is
}, and the
complementation of L1 is ![]() = {00, 01, 10, 11, 000, 001, . . . }.
= {00, 01, 10, 11, 000, 001, . . . }.
Ï ![]() L = L for each language L. Similarly, Ï
L = L for each language L. Similarly, Ï ![]() L = Ï for each language L. On the
other hand,
L = Ï for each language L. On the
other hand, ![]() =
= ![]() * and
* and ![]() = Ï for each alphabet
= Ï for each alphabet ![]() .
. ![]()
The difference of L1 and L2, denoted L1 - L2, refers to the language that consists of all the strings that are in L1 but not in L2, that is, to { x | x is in L1 but not in L2 }. The cross product of L1 and L2, denoted L1 Î L2, refers to the set of all the pairs (x, y) of strings such that x is in L1 and y is in L2, that is, to the relation { (x, y) | x is in L1 and y is in L2 }. The composition of L1 with L2, denoted L1L2, refers to the language { xy | x is in L1 and y is in L2 }.
Exampleá1.2.3 áá
If L1 = {![]() , 1, 01, 11} and L2 = {1, 01, 101} then L1 - L2 = {
, 1, 01, 11} and L2 = {1, 01, 101} then L1 - L2 = {![]() , 11} and
L2 - L1 = {101}.
, 11} and
L2 - L1 = {101}.
On the other hand, if L1 = {![]() , 0, 1} and L2 = {01, 11}, then the cross product of these
languages is L1 Î L2 = {(
, 0, 1} and L2 = {01, 11}, then the cross product of these
languages is L1 Î L2 = {(![]() , 01), (
, 01), (![]() , 11), (0, 01), (0, 11), (1, 01), (1, 11)}, and their
composition is L1L2 = {01, 11, 001, 011, 101, 111}.
, 11), (0, 01), (0, 11), (1, 01), (1, 11)}, and their
composition is L1L2 = {01, 11, 001, 011, 101, 111}.
L - Ï = L, Ï - L = Ï, ÏL = Ï, and {![]() }L = L for each language L.
}L = L for each language L. ![]()
Li will also be used to denote the composing of i copies of a language L, where L0 is
defined as {![]() }. The set L0
}. The set L0 ![]() L1
L1 ![]() L2
L2 ![]() L3 . . . , called the Kleene closure or just the
closure of L, will be denoted by L*. The set L1
L3 . . . , called the Kleene closure or just the
closure of L, will be denoted by L*. The set L1 ![]() L2
L2 ![]() L3
L3 ![]()
![]()
![]() , called the positive closure
of L, will be denoted by L+.
, called the positive closure
of L, will be denoted by L+.
Li consists of those strings that can be obtained by concatenating i strings from L. L* consists of those strings that can be obtained by concatenating an arbitrary number of strings from L.
Exampleá1.2.4 áá
Consider the pair of languages L1 = {![]() , 0, 1} and L2 = {01, 11}.
For these languages L1 2 = {
, 0, 1} and L2 = {01, 11}.
For these languages L1 2 = {![]() , 0, 1, 00, 01, 10, 11}, and
L2 3 = {010101, 010111, 011101, 011111, 110101, 110111, 111101, 111111}. In
addition,
, 0, 1, 00, 01, 10, 11}, and
L2 3 = {010101, 010111, 011101, 011111, 110101, 110111, 111101, 111111}. In
addition, ![]() is in L1*, ináL1 +, and in L2* but not in L2 +.
is in L1*, ináL1 +, and in L2* but not in L2 +. ![]()
The operations above apply in a similar way to relations in ![]() * Î
* Î ![]() *, when
*, when ![]() and
and ![]() are alphabets. Specifically, the union of the relations R1 and R2, denoted R1
are alphabets. Specifically, the union of the relations R1 and R2, denoted R1 ![]() R2, is the
relation { (x, y) | (x, y) is in R1 or in R2 }. The intersection of R1 and R2, denoted
R1
R2, is the
relation { (x, y) | (x, y) is in R1 or in R2 }. The intersection of R1 and R2, denoted
R1 ![]() R2, is the relation { (x, y) | (x, y) is in R1 and in R2 }. The composition of R1 with
R2, denoted R1R2, is the relation { (x1x2, y1y2) | (x1, y1) is in R1 and (x2, y2) is in
R2 }.
R2, is the relation { (x, y) | (x, y) is in R1 and in R2 }. The composition of R1 with
R2, denoted R1R2, is the relation { (x1x2, y1y2) | (x1, y1) is in R1 and (x2, y2) is in
R2 }.
Exampleá1.2.5 áá
Consider the relations R1 = {(![]() , 0), (10, 1)} and R2 = {(1,
, 0), (10, 1)} and R2 = {(1, ![]() ), (0, 01)}. For
these relations R1
), (0, 01)}. For
these relations R1 ![]() R2 = {(
R2 = {(![]() , 0), (10, 1), (1,
, 0), (10, 1), (1, ![]() ), (0, 01)}, R1
), (0, 01)}, R1 ![]() R2 = Ï,
R1R2 = {(1, 0), (0, 001), (101, 1), (100, 101)}, and R2R1 = {(1, 0), (110, 1), (0, 010), (010, 011)}.
R2 = Ï,
R1R2 = {(1, 0), (0, 001), (101, 1), (100, 101)}, and R2R1 = {(1, 0), (110, 1), (0, 010), (010, 011)}.
![]()
The complementation of a relation R in ![]() * Î
* Î ![]() *, or just the complementation of R
when
*, or just the complementation of R
when ![]() and
and ![]() are understood, denoted
are understood, denoted ![]() , is the relation { (x, y) | (x, y) is in
, is the relation { (x, y) | (x, y) is in ![]() * Î
* Î ![]() *
but not in R }. The inverse of R, denoted R-1, is the relation { (y, x) | (x, y) is in R }.
R0 = {(
*
but not in R }. The inverse of R, denoted R-1, is the relation { (y, x) | (x, y) is in R }.
R0 = {(![]() ,
, ![]() )}. Ri = Ri-1R for i
)}. Ri = Ri-1R for i ![]() 1.
1.
Exampleá1.2.6 áá
If R is the relation {(![]() ,
, ![]() ), (
), (![]() , 01)}, then R-1 = {(
, 01)}, then R-1 = {(![]() ,
, ![]() ), (01,
), (01, ![]() )}, R0 = {(
)}, R0 = {(![]() ,
, ![]() )}, and
R2 = {(
)}, and
R2 = {(![]() ,
, ![]() ), (
), (![]() , 01), (
, 01), (![]() , 0101)}.
, 0101)}. ![]()
A language that can be defined by a formal system, that is, by a system that has a finite number of axioms and a finite number of inference rules, is said to be a formal language.
It is often convenient to specify languages in terms of grammars. The advantage in
doing so arises mainly from the usage of a small number of rules for describing a language
with a large number of sentences. For instance, the possibility that an English sentence
consists of a subject phrase followed by a predicate phrase can be expressed by a
grammatical rule of the form <sentence> ![]() <subject><predicate>. (The names in
angular brackets are assumed to belong to the grammar metalanguage.) Similarly, the
possibility that the subject phrase consists of a noun phrase can be expressed by a
grammatical rule of the form <subject>
<subject><predicate>. (The names in
angular brackets are assumed to belong to the grammar metalanguage.) Similarly, the
possibility that the subject phrase consists of a noun phrase can be expressed by a
grammatical rule of the form <subject> ![]() <noun>. In a similar manner it can also be
deduced that "Mary sang a song" is a possible sentence in the language described by the
following grammatical rules.
<noun>. In a similar manner it can also be
deduced that "Mary sang a song" is a possible sentence in the language described by the
following grammatical rules.
The grammatical rules above also allow English sentences of the form "Mary sang a song" for other names besides Mary. On the other hand, the rules imply non-English sentences like "Mary sang a Mary," and do not allow English sentences like "Mary read a song." Therefore, the set of grammatical rules above consists of an incomplete grammatical system for specifying the English language.
For the investigation conducted here it is sufficient to consider only grammars that consist of finite sets of grammatical rules of the previous form. Such grammars are called Type 0 grammars , or phrase structure grammars , and the formal languages that they generate are called Type 0 languages.
Strictly speaking, each Type 0 grammar G is defined as a mathematical system
consisting of a quadruple <N, ![]() , P, S>, where
, P, S>, where
<N1, ![]() 1, P1, S> is not a grammar if N1 is the set of natural numbers, or
1, P1, S> is not a grammar if N1 is the set of natural numbers, or ![]() 1 is empty,
because N1 and
1 is empty,
because N1 and ![]() 1 have to be alphabets.
1 have to be alphabets.
If N2 = {S}, ![]() 2 = {a, b}, and P2 = {S
2 = {a, b}, and P2 = {S ![]() aSb, S
aSb, S ![]()
![]() , ab
, ab ![]() S} then
<N2,
S} then
<N2, ![]() 2, P2, S> is not a grammar, because ab
2, P2, S> is not a grammar, because ab ![]() S does not satisfy the requirement that
each production rule must contain at least one nonterminal symbol on the left-hand side.
S does not satisfy the requirement that
each production rule must contain at least one nonterminal symbol on the left-hand side. ![]()
In general, the nonterminal symbols of a Type 0 grammar are denoted by S and by the
first uppercase letters in the English alphabet A, B, C, D, and E. The start symbol is
denoted by S. The terminal symbols are denoted by digits and by the first lowercase
letters in the English alphabet a, b, c, d, and e. Symbols of insignificant nature are
denoted by X, Y, and Z. Strings of terminal symbols are denoted by the last
lowercase English characters u, v, w, x, y, and z. Strings that may consist of both
terminal and nonterminal symbols are denoted by the first lowercase Greek symbols
![]() ,
, ![]() , and
, and ![]() . In addition, for convenience, sequences of production rules of the
form
. In addition, for convenience, sequences of production rules of the
form
are denoted as
Exampleá1.2.8 áá
<N, ![]() , P, S> is a Type 0 grammar if N = {S, B},
, P, S> is a Type 0 grammar if N = {S, B}, ![]() = {a, b, c}, and P consists of the
following production rules.
= {a, b, c}, and P consists of the
following production rules.
The nonterminal symbol S is the left-hand side of the first three production rules. Ba is the left-hand side of the fourth production rule. Bb is the left-hand side of the fifth production rule.
The right-hand side aBSc of the first production rule contains both terminal and
nonterminal symbols. The right-hand side abc of the second production rule contains only
terminal symbols. Except for the trivial case of the right-hand side ![]() of the third
production rule, none of the right-hand sides of the production rules consists only of
nonterminal symbols, even though they are allowed to be of such a form.
of the third
production rule, none of the right-hand sides of the production rules consists only of
nonterminal symbols, even though they are allowed to be of such a form. ![]()
Grammars generate languages by repeatedly modifying given strings. Each
modification of a string is in accordance with some production rule of the grammar in
question G = <N, ![]() , P, S>. A modification to a string
, P, S>. A modification to a string ![]() in accordance with production
rule
in accordance with production
rule ![]()
![]()
![]() is derived by replacing a substring
is derived by replacing a substring ![]() in
in ![]() by
by ![]() .
.
In general, a string ![]() is said to directly derive a string
is said to directly derive a string ![]() ' if
' if ![]() ' can be obtained from
' can be obtained from ![]() by a single modification. Similarly, a string
by a single modification. Similarly, a string ![]() is said to derive
is said to derive ![]() ' if
' if ![]() ' can be obtained from
' can be obtained from
![]() by a sequence of an arbitrary number of direct derivations.
by a sequence of an arbitrary number of direct derivations.
Formally, a string ![]() is said to directly derive in G a string
is said to directly derive in G a string ![]() ', denoted
', denoted ![]()
![]() G
G![]() ', if
', if ![]() '
can be obtained from
'
can be obtained from ![]() by replacing a substring
by replacing a substring ![]() with
with ![]() , where
, where ![]()
![]()
![]() is a production
rule in G. That is, if
is a production
rule in G. That is, if ![]() =
= ![]()
![]()
![]() and
and ![]() ' =
' = ![]()
![]()
![]() for some strings
for some strings ![]() ,
, ![]() ,
, ![]() , and
, and ![]() such that
such that
![]()
![]()
![]() is a production rule in G.
is a production rule in G.
Exampleá1.2.9 áá
If G is the grammar <N, ![]() , P, S> in Exampleá1.2.7, then both
, P, S> in Exampleá1.2.7, then both ![]() and aSb are
directly derivable from S. Similarly, both ab and a2Sb2 are directly derivable from
aSb.
and aSb are
directly derivable from S. Similarly, both ab and a2Sb2 are directly derivable from
aSb. ![]() is directly derivable from S, and ab is directly derivable from aSb, in
accordance with the production rule S
is directly derivable from S, and ab is directly derivable from aSb, in
accordance with the production rule S ![]()
![]() . aSb is directly derivable from S, and
a2Sb2 is directly derivable from aSb, in accordance with the production rule
S
. aSb is directly derivable from S, and
a2Sb2 is directly derivable from aSb, in accordance with the production rule
S ![]() aSb.
aSb.
On the other hand, if G is the grammar <N, ![]() , P, S> of Exampleá1.2.8, then
aBaBabccc
, P, S> of Exampleá1.2.8, then
aBaBabccc ![]() GaaBBabccc ááand ááaBaBabccc
GaaBBabccc ááand ááaBaBabccc ![]() GaBaaBbccc in accordance with the
production rule Ba
GaBaaBbccc in accordance with the
production rule Ba ![]() aB. Moreover, no other string is directly derivable from
aBaBabccc in G.
aB. Moreover, no other string is directly derivable from
aBaBabccc in G. ![]()
![]() is said to derive
is said to derive ![]() ' in G, denoted
' in G, denoted ![]()
![]() G*
G* ![]() ', if
', if ![]() 0
0 ![]() G
G ![]()
![]()
![]()
![]() G
G![]() 'n for some
'n for some
![]() 0,á. . . ,á
0,á. . . ,á![]() n such that
n such that ![]() 0 =
0 = ![]() and
and ![]() n =
n = ![]() '. In such a case, the sequence
'. In such a case, the sequence ![]() 0
0 ![]() G
G ![]()
![]()
![]()
![]() G
G![]() n
is said to be a derivation of
n
is said to be a derivation of ![]() from
from ![]() ' whose length is equal to n.
' whose length is equal to n. ![]() 0,á. . . ,á
0,á. . . ,á![]() n are said to be
sentential forms, if
n are said to be
sentential forms, if ![]() 0 = S. A sentential form that contains no terminal symbols is said to
be a sentence .
0 = S. A sentential form that contains no terminal symbols is said to
be a sentence .
Exampleá1.2.10 áá
If G is the grammar of Exampleá1.2.7, then a4Sb4 has a derivation from S. The derivation
S ![]() G* a4Sb4 has length 4, and it has the form S
G* a4Sb4 has length 4, and it has the form S ![]() GaSb
GaSb ![]() Ga2Sb2
Ga2Sb2 ![]() Ga3Sb3
Ga3Sb3 ![]() Ga4Sb4.
Ga4Sb4. ![]()
A string is assumed to be in the language that the grammar G generates if and only if it
is a string of terminal symbols that is derivable from the starting symbol. The language
that is generated by G, denoted L(G), is the set of all the strings of terminal
symbols that can be derived from the start symbol, that is, the set { w | w is in ![]() *,
and S
*,
and S ![]() G* w }. Each string in the language L(G) is said to be generated by
G.
G* w }. Each string in the language L(G) is said to be generated by
G.
Exampleá1.2.11 áá
Consider the grammar G of Exampleá1.2.7. ![]() is in the language that G generates
because of the existence of the derivation S
is in the language that G generates
because of the existence of the derivation S ![]() G
G![]() . ab is in the language that G
generates, because of the existence of the derivation S
. ab is in the language that G
generates, because of the existence of the derivation S ![]() GaSb
GaSb ![]() Gab. a2b2
is in the language that G generates, because of the existence of the derivation
S
Gab. a2b2
is in the language that G generates, because of the existence of the derivation
S ![]() GaSb
GaSb ![]() Ga2Sb2
Ga2Sb2 ![]() Ga2b2.
Ga2b2.
The language L(G) that G generates consists of all the strings of the form
a ![]()
![]()
![]() ab
ab ![]()
![]()
![]() b in which the number of a's is equal to the number of b's, that is,
L(G)á=á{ aibi | i is a natural number }.
b in which the number of a's is equal to the number of b's, that is,
L(G)á=á{ aibi | i is a natural number }.
aSb is not in L(G) because it contains a nonterminal symbol. a2b is not in L(G)
because it cannot be derived from S in G. ![]()
In what follows, the notations ![]()
![]()
![]() ' and
' and ![]()
![]() *
* ![]() ' are used instead of
' are used instead of ![]()
![]() G
G![]() ' and
' and
![]()
![]() G*
G* ![]() ', respectively, when G is understood. In addition, Type 0 grammars are referred
to simply as grammars, and Type 0 languages are referred to simply as languages , when no
confusion arises.
', respectively, when G is understood. In addition, Type 0 grammars are referred
to simply as grammars, and Type 0 languages are referred to simply as languages , when no
confusion arises.
Exampleá1.2.12 áá If G is the grammar of Exampleá1.2.8, then the following is a derivation for a3b3c3. The underlined and the overlined substrings are the left- and the right-hand sides, respectively, of those production rules used in the derivation.
| | ||||
| | aB | |||
| | aBa | |||
| | aBa | |||
| | a | |||
| | a | |||
| | aa | |||
| | aaa | |||
The language generated by the grammar G consists of all the strings of the form
a ![]()
![]()
![]() ab
ab ![]()
![]()
![]() bc
bc ![]()
![]()
![]() c in which there are equal numbers of a's, b's, and c's, that is,
L(G)á=á{ aibici | i is a natural number }.
c in which there are equal numbers of a's, b's, and c's, that is,
L(G)á=á{ aibici | i is a natural number }.
The first two production rules in G are used for generating sentential forms
that have the pattern aBaB ![]()
![]()
![]() aBabc
aBabc ![]()
![]()
![]() c. In each such sentential form the
number of a's is equal to the number of c's and is greater by 1 than the number of
B's.
c. In each such sentential form the
number of a's is equal to the number of c's and is greater by 1 than the number of
B's.
The production rule Ba ![]() aB is used for transporting the B's rightward in the
sentential forms. The production rule Bb
aB is used for transporting the B's rightward in the
sentential forms. The production rule Bb ![]() bb is used for replacing the B's by b's, upon
reaching their appropriate positions.
bb is used for replacing the B's by b's, upon
reaching their appropriate positions. ![]()
Derivations of sentential forms in Type 0 grammars can be displayed by derivation , or
parse, graphs. Each derivation graph is a rooted, ordered, acyclic, directed graph
whose nodes are labeled. The label of each node is either a nonterminal symbol,
a terminal symbol, or an empty string. The derivation graph that corresponds
to a derivation S ![]()
![]() 1
1 ![]()
![]()
![]()
![]()
![]()
![]() n is defined inductively in the following
manner.
n is defined inductively in the following
manner.
Exampleá1.2.13 áá
Figureá1.2.1(a) provides examples of derivation trees for derivations in the grammar of
Exampleá1.2.7. Figureá1.2.1(b) provides examples of derivation graphs for derivations in the
grammar of Exampleá1.2.8. ![]()
áá
á
![[PICT]](theory-bk-one-1-2-1.jpg)
![[PICT]](theory-bk-one-1-2-2.jpg)
|
A derivation ![]() 0
0 ![]()
![]()
![]()
![]()
![]()
![]() n is said to be a leftmost derivation if
n is said to be a leftmost derivation if ![]() 1 is replaced before
1 is replaced before
![]() 2 in the derivation whenever the following two conditions hold.
2 in the derivation whenever the following two conditions hold.
On the other hand, the following derivation is a leftmost derivation for a3b3c3 in G. The order in which the production rules are used is similar to that indicated in Figureá1.2.2. The only difference is that the indices 6 and 7 should be interchanged.
| | ||||
| | a | |||
| | a | |||
| | aaB | |||
| | aa | |||
| | aa | |||
| | aaa | |||
| | aaa |
The following classes of grammars are obtained by gradually increasing the restrictions that the production rules have to obey.
A Type 1 grammar is a Type 0 grammar <N, ![]() , P, S> that satisfies the following two
conditions.
, P, S> that satisfies the following two
conditions.
Exampleá1.2.15 áá The grammar of Exampleá1.2.8 is not a Type 1 grammar, because it does not satisfy condition (b). The grammar can be modified to be of Type 1 by replacing its production rules with the following ones. E is assumed to be a new nonterminal symbol.
An addition to the modified grammar of a production rule of the form Bb ![]() b will
result in a non-Type 1 grammar, because of a violation to condition (a).
b will
result in a non-Type 1 grammar, because of a violation to condition (a). ![]()
A Type 2 grammar is a Type 1 grammar in which each production rule ![]()
![]()
![]() satisfies
|
satisfies
|![]() | = 1, that is,
| = 1, that is, ![]() is a nonterminal symbol. A language is said to be a Type 2 language if
there exists a Type 2 grammar that generates the language.
is a nonterminal symbol. A language is said to be a Type 2 language if
there exists a Type 2 grammar that generates the language.
Exampleá1.2.16 áá The grammar of Exampleá1.2.7 is not a Type 1 grammar, and therefore also not a Type 2 grammar. The grammar can be modified to be a Type 2 grammar, by replacing its production rules with the following ones. E is assumed to be a new nonterminal symbol.
An addition of a production rule of the form aE ![]() EaE to the grammar will result in
a non-Type 2 grammar.
EaE to the grammar will result in
a non-Type 2 grammar. ![]()
A Type 3 grammar is a Type 2 grammar <N, ![]() , P, S> in which each of the
production rules
, P, S> in which each of the
production rules ![]()
![]()
![]() , which is not of the form S
, which is not of the form S ![]()
![]() , satisfies one of the following
conditions.
, satisfies one of the following
conditions.
Exampleá1.2.17 áá
The grammar <N, ![]() , P, S>, which has the following production rules, is a Type
3.
, P, S>, which has the following production rules, is a Type
3.
An addition of a production rule of the form A ![]() Ba, or of the form B
Ba, or of the form B ![]() bb, to the
grammar will result in a non-Type 3 grammar.
bb, to the
grammar will result in a non-Type 3 grammar. ![]()
Figureá1.2.3 illustrates the hierarchy of the different types of grammars.
á
á
![[PICT]](theory-bk-one-1-2-3.jpg)
|