The classes of languages that are accepted by finite-state automata on the one hand and pushdown automata on the other hand were shown earlier to be the classes of Type 3 and Type 2 languages, respectively. The following two theorems show that the class of languages accepted by Turing machines is the class of Type 0 languages.
Theorem 4.6.1 Each Type 0 language is a recursively enumerable language.
Proof
Consider any Type 0 grammar G = <N, ![]() , P, S>. From G construct a two
auxiliary-work-tape Turing machine MG that on a given input x nondeterministically
generates some string w in L(G), and then accepts x if and only if x = w.
, P, S>. From G construct a two
auxiliary-work-tape Turing machine MG that on a given input x nondeterministically
generates some string w in L(G), and then accepts x if and only if x = w.
The Turing machine MG generates the string w by tracing a derivation in G of w from S. MG starts by placing the sentential form S in the first auxiliary work tape. Then MG repeatedly replaces the sentential form stored on the first auxiliary work tape with the one that succeeds it in the derivation. The second auxiliary work tape is used as an intermediate memory, while deriving the successor of each of the sentential forms.
The successor of each sentential form ![]() is obtained by nondeterministically searching
is obtained by nondeterministically searching
![]() for a substring
for a substring ![]() , such that
, such that ![]()
![]()
![]() is a production rule in G, and then replacing
is a production rule in G, and then replacing ![]() by
by ![]() in
in ![]() .
.
MG uses a subcomponent M1 to copy the prefix of ![]() that precedes
that precedes ![]() onto the second
auxiliary work tape.
onto the second
auxiliary work tape.
MG uses a subcomponent M2 to read ![]() from the first auxiliary work tape and replace
it by
from the first auxiliary work tape and replace
it by ![]() on the second.
on the second.
MG uses a subcomponent M3 to copy the suffix of ![]() that succeeds
that succeeds ![]() onto the second
auxiliary work tape.
onto the second
auxiliary work tape.
MG uses a subcomponent M4 to copy the sentential form created on the second auxiliary work tape onto the first. In addition, MG uses M4 to determine whether the new sentential form is a string in L(G). If w is in L(G), then the control is passed to a subcomponent M5. Otherwise, the control is passed to M1.
MG uses the subcomponent M5 to determine whether the input string x is equal to the
string w stored on the first auxiliary work tape. ![]()
Example 4.6.1 Consider the grammar G which has the following production rules.
The language L(G) is accepted by the Turing machine MG, whose transition diagram is given in Figure 4.6.1.
![[PICT]](theory-bk-four-4-6-1.jpg)
|
The components M1, M2, and M3 scan from left to right the sentential form stored on the first auxiliary work tape. As the components scan the tape they erase its content.
The component M2 of MG uses two different sequences of transition rules for the first
and second production rules: S ![]() aSbS and Sb
aSbS and Sb ![]()
![]() . The sequence of transition rules that
corresponds to S
. The sequence of transition rules that
corresponds to S ![]() aSbS removes S from the first auxiliary work tape and
stores aSbS on the second. The sequence of transition rules that corresponds to
Sb
aSbS removes S from the first auxiliary work tape and
stores aSbS on the second. The sequence of transition rules that corresponds to
Sb ![]()
![]() removes Sb from the first auxiliary work tape and stores nothing on the
second.
removes Sb from the first auxiliary work tape and stores nothing on the
second.
The component M4 scans from right to left the sentential form in the second auxiliary
work tape, erasing the content of the tape during the scanning. M4 starts scanning the
sentential form in its first state, determining that the sentential form is a string of terminal
symbols if it reaches the blank symbol B while in the first state. In such a case, M4
transfers the control to M5. M4 determines that the sentential form is not a string of
terminal symbols if it reaches a nonterminal symbol. In this case, M4 switches from its
first to its second state. ![]()
Theorem 4.6.2 Each recursively enumerable language is a Type 0 language.
Proof The proof consists of constructing from a given Turing machine M a grammar that can simulate the computations of M. The constructed grammar G consists of three groups of production rules.
The purpose of the first group is to determine the following three items.
The purpose of the second group of production rules is to simulate a computation of M. The simulation must start at the configuration determined by the first group. In addition, the simulation must be in accordance with the sequence of transition rules, and within the segments of the auxiliary work tapes determined by the first group.
The purpose of the third group of production rules is to extract the input whenever an accepting computation has been simulated, and to leave nonterminal symbols in the sentential form in the other cases. Consequently, the grammar can generate a given string if and only if the Turing machine M has an accepting computation on the string.
Consider any Turing machine M = <Q, ![]() ,
, ![]() ,
, ![]() , q0, B, F>. With no loss of generality
it can be assumed that M is a two auxiliary-work-tape Turing machine (see Theorem 4.3.1
and Proposition 4.3.1), that no transition rule originates at an accepting state, and that
N =
, q0, B, F>. With no loss of generality
it can be assumed that M is a two auxiliary-work-tape Turing machine (see Theorem 4.3.1
and Proposition 4.3.1), that no transition rule originates at an accepting state, and that
N = ![]()
![]() {
{ ![]() |
| ![]() is in
is in ![]() }
} ![]() { [q] | q is in Q }
{ [q] | q is in Q } ![]() {۱, $,
{۱, $, ![]() ,
, ![]() ,
, ![]() , #, S, A, C, D, E, F, K} is
a multiset whose symbols are all distinct.
, #, S, A, C, D, E, F, K} is
a multiset whose symbols are all distinct.
From M construct a grammar G = <N, ![]() , P, S> that generates L(M), by tracing in
its derivations the configurations that M goes through in its accepting computations. The
production rules in P are of the following form.
, P, S> that generates L(M), by tracing in
its derivations the configurations that M goes through in its accepting computations. The
production rules in P are of the following form.
Each such sentential form corresponds to an initial configuration
(۱q0a1 ![]()
![]()
![]() an$, q0, q0) of M, and a sequence of transition rules
an$, q0, q0) of M, and a sequence of transition rules ![]() i1
i1 ![]()
![]()
![]()
![]() it. The
transition rules define a sequence of compatible states that starts at the initial
state and ends at an accepting state.
it. The
transition rules define a sequence of compatible states that starts at the initial
state and ends at an accepting state. ![]() represents the input head,
represents the input head, ![]() represents
the head of the first auxiliary work tape, and
represents
the head of the first auxiliary work tape, and ![]() represents the head of the
second auxiliary work tape. The string B
represents the head of the
second auxiliary work tape. The string B ![]()
![]()
![]() B
B![]() B
B ![]()
![]()
![]() B corresponds to a
segment of the first auxiliary work tape, and the string B
B corresponds to a
segment of the first auxiliary work tape, and the string B ![]()
![]()
![]() B
B![]() B
B ![]()
![]()
![]() B to a
segment of the second.
B to a
segment of the second.
A string in the language is derivable from the sentential form if and only if the following three conditions hold.
The production rules for the nonterminal symbols S and A can generate a
string of the form ۱![]() a1
a1 ![]()
![]()
![]() an$C for each possible input a1
an$C for each possible input a1 ![]()
![]()
![]() an of M. The
production rules for the nonterminal symbols C and D can generate a string of
the form B
an of M. The
production rules for the nonterminal symbols C and D can generate a string of
the form B ![]()
![]()
![]() B
B![]() B
B ![]()
![]()
![]() B#E for each possible segment B
B#E for each possible segment B ![]()
![]()
![]() B
B![]() B
B ![]()
![]()
![]() B
of the first auxiliary work tape that contains the corresponding head location.
The production rules for E and F can generate a string of the form
B
B
of the first auxiliary work tape that contains the corresponding head location.
The production rules for E and F can generate a string of the form
B ![]()
![]()
![]() B
B![]() B
B ![]()
![]()
![]() B#[q0] for each possible segment B
B#[q0] for each possible segment B ![]()
![]()
![]() B
B![]() B
B ![]()
![]()
![]() B of the
second tape that contains the corresponding head location. The production
rules for the nonterminal symbols that correspond to the states of M can
generate any sequence
B of the
second tape that contains the corresponding head location. The production
rules for the nonterminal symbols that correspond to the states of M can
generate any sequence ![]() i1
i1 ![]()
![]()
![]()
![]() it of transition rules of M that starts at the
initial state, ends at an accepting state, and is compatible in the transition
between the states.
it of transition rules of M that starts at the
initial state, ends at an accepting state, and is compatible in the transition
between the states.
which corresponds to configuration ![]() = (uqv$, u1qv1, u2qv2), a sentential
form
= (uqv$, u1qv1, u2qv2), a sentential
form
which corresponds to configuration ![]() = (ﻳ
= (ﻳ![]()
![]() $, ﻳ1
$, ﻳ1![]()
![]() 1, ﻳ2
1, ﻳ2![]()
![]() 2).
2). ![]() and
and ![]() are
assumed to be two configurations of M such that
are
assumed to be two configurations of M such that ![]() is reachable from
is reachable from ![]() by a
move that uses the transition rule
by a
move that uses the transition rule ![]() ij.
ij.
For each transition rule ![]() the set of production rules have
the set of production rules have
of a configuration of M. ![]() gets across the head symbols
gets across the head symbols ![]() ,
, ![]() , and
, and ![]() by using the production rules in (2) through (7). As
by using the production rules in (2) through (7). As ![]() gets across the head
symbols, the production rules in (2) through (7) "simulate" the changes in the
tapes of M, and the corresponding heads position, because of the transition
rule
gets across the head
symbols, the production rules in (2) through (7) "simulate" the changes in the
tapes of M, and the corresponding heads position, because of the transition
rule ![]() .
.
which corresponds to an accepting configuration of M, the input that M accepts. The production rules are as follows.
![]()
Example 4.6.2 Let M be the Turing machine whose transition diagram is given in Figure 4.5.6(a). L(M) is generated by the grammar G that consists of the following production rules.
The string abc has a leftmost derivation of the following form in G.
![]()
Theorem 4.6.2, together with Theorem 4.5.3, implies the following result.
Corollary 4.6.1 The membership problem is undecidable for Type 0 grammars or, equivalently, for { (G, x) | G is a Type 0 grammar, and x is in L(G) }.
A context-sensitive grammar is a Type 1 grammar in which each production rule has
the form ![]() 1A
1A![]() 2
2 ![]()
![]() 1
1![]()
![]() 2 for some nonterminal symbol A. Intuitively, a production rule
of the form
2 for some nonterminal symbol A. Intuitively, a production rule
of the form ![]() 1A
1A![]() 2
2 ![]()
![]() 1
1![]()
![]() 2 indicates that A
2 indicates that A ![]()
![]() can be used only if it is
within the left context of
can be used only if it is
within the left context of ![]() 1 and the right context of
1 and the right context of ![]() 2. A language is said to
be a context-sensitive language, if it can be generated by a context-sensitive
grammar.
2. A language is said to
be a context-sensitive language, if it can be generated by a context-sensitive
grammar.
A language is context-sensitive if and only if it is a Type 1 language (Exercise 4.6.4),
and if and only if it is accepted by a linear bounded automaton (Exercise 4.6.5). By
definition and Theorem 3.3.1, each context-free language is also context-sensitive, but
the converse is false because the non-context-free language { aibici | i ![]() 0 } is
context-sensitive. It can also be shown that each context-sensitive language is recursive
(Exercise 1.4.4), and that the recursive language LLBA_reject = { x | x = xi and Mi does
not have accepting computations on input xi in which at most |xi| locations are visited in
each auxiliary work tape } is not context-sensitive (Exercise 4.5.6).
0 } is
context-sensitive. It can also be shown that each context-sensitive language is recursive
(Exercise 1.4.4), and that the recursive language LLBA_reject = { x | x = xi and Mi does
not have accepting computations on input xi in which at most |xi| locations are visited in
each auxiliary work tape } is not context-sensitive (Exercise 4.5.6).
Figure 4.6.2
![[PICT]](theory-bk-four-4-6-2.jpg)
|
![S --> c|0 A
A --> aA Foreachinputsymbol ainS.
--> $C
C --> BC
--> |1 D
D --> BD
--> #E
E --> BE
--> |2 F
F --> BF
--> #[q ] Fortheinitialstateq .
[q] --> t[p0] For each pair q and 0p of states, and for each
transition rulet,suchthatt leavesstate qand
entersstatep.
[q ] --> e Foreachacceptingstateq .
f f](theory-bk-four38x.gif)

![|| |
S --> c-0 A D --> BD [q0] --> t1[q0]
A --> aA --> #E --> t2[q0]
--> bA E --> BE| --> t3[q1]
--> cA --> -2 F [q1] --> t4[q1]
--> $C F --> BF --> t5[q2]
C --> BC| --> #[q0] [q2] --> e
--> -1 D](theory-bk-four77x.gif)

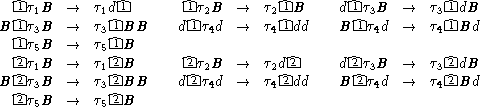
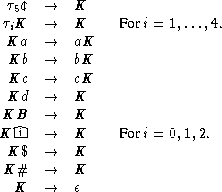
![S ==> c|0 A
==>* c|0 abc$C
==>* c|0 abc$B 1|BB#E
==>* c|0 abc$B 1|BB#B 2|BB#[q0]
==>* c|0 abc$B 1|BB#B 2|BB#t1t2t3t4t5 The sententialforms
==>* t1ca|0 bc$Bd|1 B#B 2-BB#t2t3t4t5 inthederivation,
==>* t1t2cab 0|c$Bd|1 B#Bd 2 B#t3t4t5 thatcorrespond to
==>* t1t2t3cab 0 c$B 1|dB#B|2 dB#t4t5 theconfigurations
==>* tt t tcabc|0 $ 1-BdB#|2 BdB#t inthesimulated
==>* 1tt2t34tt cabc 0|$ 1 BdB#|2 BdB# 5 computationof M.
==>* 1tt2t34tK5abc 0|$ 1|BdB#|2 BdB#
==>* 1Ka2bc340 $ 1-BdB#|2 BdB#
==>* abcK |1 BdB# 2 BdB#
==>* abcK |2 BdB#
==>* abcK
==> abc](theory-bk-four82x.gif)