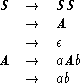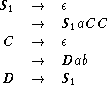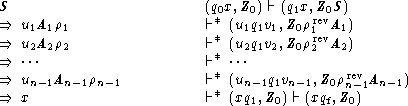ĀĀĀĀĀĀFrom Context-Free Grammars to Type 2 Grammars
ĀĀĀĀĀĀFrom Context-Free Grammars to Pushdown Automata
ĀĀĀĀĀĀFrom Context-Free Grammars to Recursive Finite-Domain Programs
ĀĀĀĀĀĀFrom Recursive Finite-Domain Programs to Context-FreeGrammars
ĀĀĀĀĀĀThe Nonterminal Symbols of G
ĀĀĀĀĀĀThe Production Rules of G
ĀĀĀĀĀĀL(G) is Contained in L(P)
ĀĀĀĀĀĀL(P) is Contained in L(G)
Pushdown automata can be characterized by Type 2 grammars or, equivalently, by context-free grammars.
Specifically, a Type 0 grammar G = <N, ![]() , P, S> is said to be context-free if each of
its production rules has exactly one nonterminal symbol on its left hand side, that is, if
each of its production rules is of the form A
, P, S> is said to be context-free if each of
its production rules has exactly one nonterminal symbol on its left hand side, that is, if
each of its production rules is of the form A ![]()
![]() .
.
The grammar is called context-free because it provides no mechanism to restrict the
usage of a production rule A ![]()
![]() within some specific context. However, in a Type 0
grammar such a restriction can be achieved by using a production rule of the form
within some specific context. However, in a Type 0
grammar such a restriction can be achieved by using a production rule of the form
![]() A
A![]()
![]()
![]()
![]()
![]() to specify that A
to specify that A ![]()
![]() is to be used only within the context of
is to be used only within the context of ![]() and
and
![]() .
.
The languages that context-free grammars generate are called context-free languages.
ExampleĀ3.3.1 ĀĀ
The language { ai1bi1ai2bi2 ![]()
![]()
![]() ainbin | n, i1,Ā. . . ,Āin
ainbin | n, i1,Ā. . . ,Āin ![]() 0 } is generated by the context-free
grammar <N,
0 } is generated by the context-free
grammar <N, ![]() , P, S>, whose production rules are given below.
, P, S>, whose production rules are given below.
![]()
ĀFrom Context-Free Grammars to Type 2 Grammars
Recall that a Type 2 grammar is a context-free grammar G = <N, ![]() , P, S> in which
A
, P, S> in which
A ![]()
![]() in P implies that A = S and that no right-hand side of the production rules
contains S. By the following theorem it follows that context-free grammars and Type
2 grammars act as "maximal" and "minimal" grammars for the same class of
languages.
in P implies that A = S and that no right-hand side of the production rules
contains S. By the following theorem it follows that context-free grammars and Type
2 grammars act as "maximal" and "minimal" grammars for the same class of
languages.
TheoremĀ3.3.1 ĀĀ Each context-free language is also a Type 2 language.
ProofĀ ĀĀ
Consider any context-free grammar G1 = <N, ![]() , P1, S1>. A Type 2 grammar
G2 = <N
, P1, S1>. A Type 2 grammar
G2 = <N ![]() {S2},
{S2}, ![]() , P2, S2> satisfies L(G2) = L(G1), if S2 is a new symbol and P2 is
obtained from P1 in the following way.
, P2, S2> satisfies L(G2) = L(G1), if S2 is a new symbol and P2 is
obtained from P1 in the following way.
Initialize P2 to equal P1 ![]() {S2
{S2 ![]() S1}. Then, as long as P2 contains a production
rule of the form A
S1}. Then, as long as P2 contains a production
rule of the form A ![]()
![]() for some A
for some A![]() S2, modify P2 as follows.
S2, modify P2 as follows.
Similarly, no deletion of a production rule A ![]()
![]() from P2 affects the generated
language, because each subderivation C
from P2 affects the generated
language, because each subderivation C ![]()
![]() 1A
1A![]() 2
2 ![]() *
* ![]() 1A
1A![]() 2
2 ![]()
![]() 1
1![]() 2 which uses
A
2 which uses
A ![]()
![]() can be replaced with an equivalent subderivation of the form C
can be replaced with an equivalent subderivation of the form C ![]()
![]() 1
1![]() 2
2 ![]() *
* ![]() 1
1![]() 2.
2.
![]()
ExampleĀ3.3.2 ĀĀ Let G1 be the context-free grammar whose production rules are listed below.
The construction in the proof of TheoremĀ3.3.1 implies the following equivalent grammars, where G2 is a Type 2 grammar.
![]()
ĀFrom Context-Free Grammars to Pushdown Automata
Pushdown automata and recursive finite-domain programs process their inputs from left to right. To enable such entities to trace derivations of context-free grammars, the following lemma considers a similar property in the derivations of context-free grammars.
LemmaĀ3.3.1 ĀĀ
If a nonterminal symbol A derives a string ![]() of terminal symbols in a context-free
grammar G, then
of terminal symbols in a context-free
grammar G, then ![]() has a leftmost derivation from A in G.
has a leftmost derivation from A in G.
ProofĀ ĀĀ
The proof is by contradiction. Recall that in context-free grammars the leftmost
derivations ![]() 1
1 ![]()
![]() 2
2 ![]()
![]()
![]()
![]()
![]()
![]() n replace the leftmost nonterminal symbol in each
sentential form
n replace the leftmost nonterminal symbol in each
sentential form ![]() i, i = 1, 2, . . . , n - 1.
i, i = 1, 2, . . . , n - 1.
The proof relies on the observation that the ordering in which the nonterminal symbols are replaced in the sentential forms is of no importance for the derivations in context-free grammars. Each nonterminal symbol in each sentential form is expanded without any correlation to its context in the sentential form.
Consider any context-free grammar G. For the purpose of the proof assume that a
string ![]() of terminal symbols has a derivation of length n from a nonterminal symbol A. In
addition, assume that
of terminal symbols has a derivation of length n from a nonterminal symbol A. In
addition, assume that ![]() has no leftmost derivation from A.
has no leftmost derivation from A.
Let A ![]()
![]() 1
1 ![]()
![]()
![]()
![]()
![]()
![]() m
m ![]()
![]()
![]()
![]()
![]()
![]() n =
n = ![]() be a derivation of length n in which
A
be a derivation of length n in which
A ![]()
![]() 1
1 ![]()
![]()
![]()
![]()
![]()
![]() m is a leftmost subderivation. In addition, assume that m is maximized
over the derivations A
m is a leftmost subderivation. In addition, assume that m is maximized
over the derivations A ![]() *
* ![]() of length n. By the assumption that
of length n. By the assumption that ![]() has no leftmost
derivation from A, it follows that m < n - 1.
has no leftmost
derivation from A, it follows that m < n - 1.
The derivation in question satisfies ![]() m = wB
m = wB![]() m,
m, ![]() m+1 = wB
m+1 = wB![]() m+1,Ā. . . ,Ā
m+1,Ā. . . ,Ā![]() k = wB
k = wB![]() k,
k, ![]() k+1 = w
k+1 = w![]()
![]() k
for some string w of terminal symbols, production rule B
k
for some string w of terminal symbols, production rule B ![]()
![]() , m < k < n, and
, m < k < n, and ![]() m,Ā. . . ,Ā
m,Ā. . . ,Ā![]() k. Thus
A
k. Thus
A ![]()
![]() 1
1 ![]()
![]()
![]()
![]()
![]()
![]() m-1
m-1 ![]()
![]() m = wB
m = wB![]() m
m ![]() w
w![]()
![]() m
m ![]() w
w![]()
![]() m+1
m+1 ![]()
![]()
![]()
![]()
![]() w
w![]()
![]() k =
k = ![]() k+1
k+1 ![]()
![]()
![]()
![]()
![]()
![]() n =
n = ![]() is also a derivation of
is also a derivation of ![]() from A of length n.
from A of length n.
However, in this new derivation A ![]()
![]() 1
1 ![]()
![]()
![]()
![]()
![]()
![]() m
m ![]() w
w![]()
![]() m is a leftmost
subderivation of length m + 1. Consequently, contradicting the existence of a maximal m
as implied above, from the assumption that
m is a leftmost
subderivation of length m + 1. Consequently, contradicting the existence of a maximal m
as implied above, from the assumption that ![]() has only nonleftmost derivations from
A.
has only nonleftmost derivations from
A.
As a result, the assumption that ![]() has no leftmost derivation from A is also
contradicted.
has no leftmost derivation from A is also
contradicted. ![]()
The proof of the following theorem shows how pushdown automata can trace the derivations of context-free grammars.
TheoremĀ3.3.2 ĀĀ Each context-free language is accepted by a pushdown automaton.
ProofĀ ĀĀ
Consider any context-free grammar G = <N, ![]() , P, S>. With no loss of generality
assume that Z0 is not in N
, P, S>. With no loss of generality
assume that Z0 is not in N ![]()
![]() . L(G) is accepted by the pushdown automaton
M = <Q,
. L(G) is accepted by the pushdown automaton
M = <Q, ![]() , N
, N ![]()
![]()
![]() {Z0},
{Z0}, ![]() , q0, Z0, {qf}> whose transition table
, q0, Z0, {qf}> whose transition table ![]() consists of the
following derivation rules.
consists of the
following derivation rules.
The transition rule in (a) is used for pushing the first sentential form S into the pushdown store. The transition rules in (b) are used for replacing the leftmost nonterminal symbol in a given sentential form with the right-hand side of an appropriate production rule. The transition rules in (c) are used for matching the leading terminal symbols in the sentential forms with the corresponding symbols in the given input x. The purpose of the production rule in (d) is to move the pushdown automaton into an accepting state upon reaching the end of a derivation.
By induction on n it can be verified that x has a leftmost derivation in G if and only if
M has an accepting computation on x, where the derivation and the computation have the
following forms with uivi = x for 1 ![]() i < n.
i < n.
![]()
ExampleĀ3.3.3 ĀĀ If G is the context-free grammar of ExampleĀ3.3.1, then the language L(G) is accepted by the pushdown automaton M, whose transition diagram is given in FigureĀ3.3.1(a).
Ā
![[PICT]](theory-bk-three-3-3-1-a.jpg) (a)
(a)
![[PICT]](theory-bk-three-3-3-1-b.jpg) (b)
Ā
(b)
Ā
|
aabbab has the leftmost derivation S ![]() SS
SS ![]() AS
AS ![]() aAbS
aAbS ![]() aabbS
aabbS ![]() aabbA
aabbA ![]() aabbab
in G. FigureĀ3.3.1(b) shows the corresponding configurations of M in its computation on
such an input.
aabbab
in G. FigureĀ3.3.1(b) shows the corresponding configurations of M in its computation on
such an input. ![]()
ĀFrom Context-Free Grammars to Recursive Finite-Domain
Programs
By TheoremsĀ3.2.1 andĀ3.3.2 each context-free language is accepted by a recursive
finite-domain program. For a given context-free grammar G = <N, ![]() , P, S>, the
recursive finite-domain program T that accepts L(G) can be of the following
form.
, P, S>, the
recursive finite-domain program T that accepts L(G) can be of the following
form.
T on a given input x nondeterministically traces a leftmost derivation that starts at S. If the leftmost derivation provides the string x, then T accepts its input. Otherwise, T rejects the input.
T has one procedure for each nonterminal symbol in N, and one procedure for each
terminal symbol in ![]() . A procedure that corresponds to a nonterminal symbol A is
responsible for initiating a tracing of a leftmost subderivation that starts at A. The
procedure does so by nondeterministically choosing a production rule of the form
A
. A procedure that corresponds to a nonterminal symbol A is
responsible for initiating a tracing of a leftmost subderivation that starts at A. The
procedure does so by nondeterministically choosing a production rule of the form
A ![]() X1
X1 ![]()
![]()
![]() Xm, and then calling the procedures that correspond to X1,Ā. . . ,ĀXm in the
given order. On the other hand, each procedure that corresponds to a terminal symbol is
responsible for reading an input symbol and verifying that the symbol is equal to its
corresponding terminal symbol.
Xm, and then calling the procedures that correspond to X1,Ā. . . ,ĀXm in the
given order. On the other hand, each procedure that corresponds to a terminal symbol is
responsible for reading an input symbol and verifying that the symbol is equal to its
corresponding terminal symbol.
Each of the procedures above returns the control to the point of invocation, upon successfully completing the given responsibilities. However, each of the procedures terminates the computation at a nonaccepting configuration upon determining that the given responsibility cannot be carried out.
The main program starts a computation by invoking the procedure that corresponds to the start symbol S. Upon the return of control the main program terminates the computation, where the termination is in an accepting configuration if and only if the remainder of the input is empty.
The recursive finite-domain program T can be as depicted in FigureĀ3.3.2.
Ā
|
ExampleĀ3.3.4 ĀĀ If G is the context-free grammar of ExampleĀ3.3.1, then L(G) is accepted by the recursive finite-domain program in FigureĀ3.3.3.
Ā
|
On input aabbab the recursive finite-domain program traces the derivation
S ![]() SS
SS ![]() AS
AS ![]() aAbS
aAbS ![]() aabbS
aabbS ![]() aabbA
aabbA ![]() aabbab by calling its procedures in the
order indicated in FigureĀ3.3.4.
aabbab by calling its procedures in the
order indicated in FigureĀ3.3.4. ![]()
Ā
Ā
![[PICT]](theory-bk-three-3-3-4.jpg)
|
ĀFrom Recursive Finite-Domain Programs to Context-Free
Grammars
A close look at the proof of TheoremĀ2.3.2 indicates how a given finite-memory
program P can be simulated by a Type 3 grammar G = <N, ![]() , P, S>.
, P, S>.
The grammar uses its nonterminal symbols to record the states of P. Each production
rule of the form A ![]() aB in the grammar is used to simulate a subcomputation of P
that starts at the state recorded by A, ends at the state recorded by B, and reads
an input symbol a. However, each production rule of the form A
aB in the grammar is used to simulate a subcomputation of P
that starts at the state recorded by A, ends at the state recorded by B, and reads
an input symbol a. However, each production rule of the form A ![]() a in the
grammar is used to simulate a subcomputation of P that starts at the state that is
recorded by A, ends at an accepting state, and reads an input symbolĀa. The start
symbol S of G is used to record the initial state of P. The production rule S
a in the
grammar is used to simulate a subcomputation of P that starts at the state that is
recorded by A, ends at an accepting state, and reads an input symbolĀa. The start
symbol S of G is used to record the initial state of P. The production rule S ![]()
![]() is used to simulate an accepting computation of P in which no input value is
read.
is used to simulate an accepting computation of P in which no input value is
read.
The proof of the following theorem relies on a similar approach.
TheoremĀ3.3.3 ĀĀ Every language that is accepted by a recursive finite-domain program is a context-free language.
ProofĀ ĀĀ Consider any recursive finite-domain program P. With no loss of generality it can be assumed that the program has no write instructions. The language that is accepted by P can be generated by a context-free grammar G that simulates the computations of P. The nonterminal symbols of G are used to indicate the start and end states of subcomputations of P that have to be simulated, and the production rules of G are used for simulating transitions between states of P.
Specifically, the nonterminal symbols of G consist of
The start symbol of G is the nonterminal symbol Aq0 that corresponds to the initial state q0 of P.
The production rules of G consist of
A production rule of the form Aq ![]()
![]() Ar replaces the objective of reaching
an accepting state from state q with the objective of reaching an accepting
state from state r.
Ar replaces the objective of reaching
an accepting state from state q with the objective of reaching an accepting
state from state r.
A production rule of the form Aq,p ![]()
![]() Ar,p replaces the objective of
reaching state p from state q with the objective of reaching state p from state
r.
Ar,p replaces the objective of
reaching state p from state q with the objective of reaching state p from state
r.
Each of the production rules above is used for terminating a successful simulation of a subcomputation performed by an invoked procedure.
A proof by induction can be used to show that the construction above implies L(G) = L(P).
To show that L(G), is contained in L(P) it is sufficient to show that the following two
conditions hold for each string ![]() of terminal symbols.
of terminal symbols.
The proof can be by induction on the number of steps i in the derivations. For i = 1, the
only feasible derivations are those that have either the form Aq ![]()
![]() or the form Ap,p
or the form Ap,p ![]()
![]() .
In the first case q corresponds to an accept instruction, and in the second case p
corresponds to a return instruction. In both cases the subexecution sequences of the
program are empty.
.
In the first case q corresponds to an accept instruction, and in the second case p
corresponds to a return instruction. In both cases the subexecution sequences of the
program are empty.
For i > 1 the derivations must have either of the following forms.
To show that L(P) is contained in L(G) it is sufficient to show that either of the
following conditions holds for each subexecution sequence that reads ![]() , starts at state q,
ends at state p, and has at least as many executions of return instructions as of call
instructions in each of the prefixes.
, starts at state q,
ends at state p, and has at least as many executions of return instructions as of call
instructions in each of the prefixes.
For i > 0 either of the following cases must hold.
Consequently, by definition, the grammar G has a production rule of the form
Aq ![]()
![]() 1Ar if p is an accepting state, and a production rule of the form
Aq,p
1Ar if p is an accepting state, and a production rule of the form
Aq,p ![]()
![]() 1Ar,p if p corresponds to a return instruction.
1Ar,p if p corresponds to a return instruction.
However, by the induction hypothesis the i-1 moves that start in state r have
in G a corresponding derivation of the form Ar ![]() *
* ![]() 2 if p is an accepting
state, and of the form Ar,p
2 if p is an accepting
state, and of the form Ar,p ![]() *
* ![]() 2 if p corresponds to a return instruction.
2 if p corresponds to a return instruction. ![]() 2
is assumed to satisfy
2
is assumed to satisfy ![]() 1
1![]() 2 =
2 = ![]() .
.
Consequently, by definition, the grammar G has a production rule of the form
Aq ![]() Ar,sAt if p is an accepting state, and a production rule of the form
Aq,p
Ar,sAt if p is an accepting state, and a production rule of the form
Aq,p ![]() Ar,sAt,p if p corresponds to a return instruction.
Ar,sAt,p if p corresponds to a return instruction.
However, by the induction hypothesis, the grammar G has a derivation of the
form Ar,s ![]() *
* ![]() 1 for the input
1 for the input ![]() 1 that the subexecution sequence consumes
between states r and s. In addition, G has either a derivation of the form
At
1 that the subexecution sequence consumes
between states r and s. In addition, G has either a derivation of the form
At ![]() *
* ![]() 2 or a derivation of the form At,p
2 or a derivation of the form At,p ![]() *
* ![]() 2, respectively, for the input
2, respectively, for the input
![]() 2 that the subexecution sequence consumes between states t andĀp, depending
on whether p is an accepting state or not.
2 that the subexecution sequence consumes between states t andĀp, depending
on whether p is an accepting state or not. ![]()
ExampleĀ3.3.5 ĀĀ Let P be the recursive finite-domain program in FigureĀ3.3.5(a), with {a, b} as a domain of the variables and a as initial value.
Ā
![A[1,a] --> A[4,a] A[4,b],[5,a] --> A[5,b],[5,a]
--> A[4,a],[5,a]A[2,a] --> A[6,b],[5,a]
--> A[4,a],[5,b]A[2,b] A[4,b],[5,b] --> A[5,b],[5,b]
A[2,a] --> e --> A[6,b],[5,b]
--> A[3,a] A[5,a],[5,a] --> e
A[2,b] --> e A[5,b],[5,b] --> e
--> A[3,b] A[6,a],[5,a] --> aA[7,a],[5,a]
A[4,a] --> A[5,a] --> bA[7,b],[5,a]
--> A[6,a] A[6,a],[5,b] --> aA[7,a],[5,b]
A[4,b] --> A[5,b] --> bA[7,b],[5,b]
--> A[6,b] A[6,b],[5,a] --> aA[7,a],[5,a]
A[6,a] --> aA[7,a] --> bA[7,b],[5,a]
--> bA[7,b] A[6,b],[5,b] --> aA[7,a],[5,b]
A[6,b] --> aA[7,a] --> bA[7,b],[5,b]
--> bA[7,b] A[7,a],[5,a] --> A[4,a],[5,a]A[8,a],[5,a]
A[7,a] --> A[4,a],[5,a]A[8,a] --> A[4,a],[5,b]A[8,b],[5,a]
--> A[4,a],[5,b]A[8,b] A[7,a],[5,b] --> A[4,a],[5,a]A[8,a],[5,b]
A[7,b] --> A[4,b],[5,a]A[8,a] --> A[4,a],[5,b]A[8,b],[5,b]
--> A[4,b],[5,b]A[8,b] A[7,b],[5,a] --> A[4,b],[5,a]A[8,a],[5,a]
A[8,b] --> A[4,b] --> A[4,b],[5,b]A[8,b],[5,a]
A[4,a],[5,a] --> A[5,a],[5,a] A[7,b],[5,b] --> A[4,b],[5,a]A[8,a],[5,b]
--> A[6,a],[5,a] --> A[4,b],[5,b]A[8,b],[5,b]
A[4,a],[5,b] --> A[5,a],[5,b] A[8,b],[5,a] --> A[4,b],[5,a]
--> A[6,a],[5,b] A[8,b],[5,b] --> A[4,b],[5,b]](theory-bk-three37x.gif)
|
L(P) is generated by the grammar G, which has the production rules in FigureĀ3.3.5(b). [i, x] denotes a state of P that corresponds to the instruction segment Ii, and value x in x.
The derivation tree for the string abb in the grammar G, and the corresponding
transitions between the states of the program P on input "a, b, b", are shown in FigureĀ3.3.6.
The symbol A[1,a] states that the computation of P has to start at state [1, a] and end at an
accepting state. The production rule A[1,a] ![]() A[4,a][5,b]A[2,b] corresponds to a call to f
which returns the value b.
A[4,a][5,b]A[2,b] corresponds to a call to f
which returns the value b. ![]()
Ā
Ā
![[PICT]](theory-bk-three-3-3-6.jpg)
|
Context-free grammars do not resemble pushdown automata, the way Type 3 grammars resemble finite-state automata. The difference arises because derivations in context-free grammars are recursive in nature, whereas computations of pushdown automata are iterative.
Consequently, some context-free languages can be more easily characterized by context-free grammars, and other context-free languages can be more easily characterized by pushdown automata.