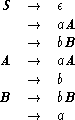ĀĀĀĀĀĀFinite-State Automata
ĀĀĀĀĀĀNondeterminism versus Determinism in Finite-State Automata
ĀĀĀĀĀĀFinite-State Automata and Type 3 Grammars
ĀĀĀĀĀĀType 3 Grammars and Regular Grammars
ĀĀĀĀĀĀRegular Languages and Regular Expressions
The computations of programs are driven by their inputs. The outputs are just the results of the computations, and they have no influence on the course that the computations take. Consequently, it seems that much can be studied about finite-state transducers, or equivalently, about finite-memory programs even when their outputs are ignored. The advantage of conducting a study of such stripped-down finite-state transducers is in the simplified argumentation that they allow.
A finite-state transducer whose output components are ignored is called a finite-state
automaton. Formally, a finite-state automaton M is a tuple <Q, ![]() ,
, ![]() , q0, F>, where Q,
, q0, F>, where Q, ![]() ,
q0, and F are defined as for finite-state transducers, and the transition table
,
q0, and F are defined as for finite-state transducers, and the transition table ![]() is a relation
from Q ū (
is a relation
from Q ū (![]()
![]() {
{![]() }) to Q.
}) to Q.
Transition diagrams similar to those used for representing finite-state transducers can
also be used to represent finite-state automata. The only difference is that in the case of
finite-state automata, an edge that corresponds to a transition rule (p, ![]() , p) is labeled by
the string
, p) is labeled by
the string ![]() .
.
ExampleĀ2.3.1 ĀĀ
The finite-state automaton that is induced by the finite-state transducer
of FigureĀ2.2.2 is <Q, ![]() ,
, ![]() , q0, F>, where Q = {q0, q1},
, q0, F>, where Q = {q0, q1}, ![]() = {a, b},
= {a, b},
![]() = {(q0, a, q1), (q0, b, q1), (q1, b, q1), (q1, a, q0)}, and F = {q0}.
= {(q0, a, q1), (q0, b, q1), (q1, b, q1), (q1, a, q0)}, and F = {q0}.
The transition diagram in FigureĀ2.3.1 represents the finite-state automaton. ![]()
Ā
Ā
![[PICT]](theory-bk-two-2-3-1.jpg)
|
The finite-state automaton M is said to be deterministic if, for each state q in Q and for
each input symbol a in ![]() , the union
, the union ![]() (q, a)
(q, a) ![]()
![]() (q,
(q, ![]() ) is a multiset that contains at most one
element. The finite-state automaton is said to be nondeterministic if it is not a deterministic
finite-state automaton.
) is a multiset that contains at most one
element. The finite-state automaton is said to be nondeterministic if it is not a deterministic
finite-state automaton.
A transition rule (q, ![]() , p) of the finite-state automaton is said to be an
, p) of the finite-state automaton is said to be an ![]() transition rule
if
transition rule
if ![]() =
= ![]() . A finite-state automaton with no
. A finite-state automaton with no ![]() transition rules is said to be an
transition rules is said to be an ![]() -free
finite-state automaton.
-free
finite-state automaton.
ExampleĀ2.3.2 ĀĀ
Consider the finite-state automaton M1 = <{q0, . . . , q6}, {0, 1},
{(q0, 0, q0), (q0, ![]() , q1), (q0,
, q1), (q0, ![]() , q4), (q1, 0, q2), (q1, 1, q1), (q2, 0, q3), (q2, 1, q2), (q3,
0, q3), (q3, 1, q1), (q4, 0, q4), (q4, 1, q5), (q5, 0, q5), (q5, 1, q6), (q6, 1, q6), (q6, 0, q4)},
q0, {q0, q3, q6}>. The transition diagram of M1 is given in FigureĀ2.3.2.
, q4), (q1, 0, q2), (q1, 1, q1), (q2, 0, q3), (q2, 1, q2), (q3,
0, q3), (q3, 1, q1), (q4, 0, q4), (q4, 1, q5), (q5, 0, q5), (q5, 1, q6), (q6, 1, q6), (q6, 0, q4)},
q0, {q0, q3, q6}>. The transition diagram of M1 is given in FigureĀ2.3.2.
Ā
Ā
![[PICT]](theory-bk-two-2-3-2.jpg)
|
M1 is nondeterministic owing to the transition rules that originate at state q0. One of the transition rules requires that an input value be read, whereas the other two transition rules require that no input value be read. Moreover, M1 is also nondeterministic when the transition rule (q0, 0, q0) is ignored, because M1 cannot determine locally which of the other transition rules to follow on the moves that originate at state q0.
The finite-state automaton M2 in FigureĀ2.3.3 is a deterministic finite-state automaton.
Ā
Ā
![[PICT]](theory-bk-two-2-3-3.jpg)
|
M1 has two ![]() transition rules, and M2 has one.
transition rules, and M2 has one. ![]()
A configuration , or an instantaneous description, of the finite-state automaton is a
singleton uqv, where q is a state in Q, and uv is a string in ![]() *. The configuration is said to
be an initial configuration if u =
*. The configuration is said to
be an initial configuration if u = ![]() and q is the initial state. The configuration is said to be
an accepting , or final, configuration if v =
and q is the initial state. The configuration is said to be
an accepting , or final, configuration if v = ![]() and q is an accepting state. With no loss of
generality it is assumed that Q and
and q is an accepting state. With no loss of
generality it is assumed that Q and ![]() are mutually disjoint.
are mutually disjoint.
Other definitions, like those of ![]() M ,
M , ![]() ,
, ![]() M *,
M *, ![]() *, and acceptance, recognition, and
decidability of a language by a finite-state automaton, are similar to those given for
finite-state transducers.
*, and acceptance, recognition, and
decidability of a language by a finite-state automaton, are similar to those given for
finite-state transducers.
ĀNondeterminism versus Determinism in Finite-State Automata
By the following theorem, nondeterminism does not add to the recognition power of finite-state automata, even though it might add to their succinctness. The proof of the theorem provides an algorithm for constructing, from any given n-state finite-state automaton, an equivalent deterministic finite-state automaton of at most 2n states.
TheoremĀ2.3.1 ĀĀ
If a language is accepted by a finite-state automaton, then it is also decided by a
deterministic finite-state automaton that has no ![]() transition rules.
transition rules.
ProofĀ ĀĀ
Consider any finite-state automaton M = <Q, ![]() ,
, ![]() , q0, F>. Let Ax denote the set of all
the states that M can reach from its initial state q0, by the sequences of moves that
consume the string x, that is, the set { q | q0x
, q0, F>. Let Ax denote the set of all
the states that M can reach from its initial state q0, by the sequences of moves that
consume the string x, that is, the set { q | q0x ![]() * xq }. Then an input w is accepted by M
if and only if Aw contains an accepting state.
* xq }. Then an input w is accepted by M
if and only if Aw contains an accepting state.
The proof relies on the observation that Axa contains exactly those states that can be
reached from the states in Ax, by the sequences of transition rules that consume a, that is,
AxaĀ=Ā{ p | q is in Ax, and qa ![]() * ap }.
* ap }.
Specifically, if p is a state in Axa, then by definition there is a sequence of transition
rules ![]() 1,Ā. . . ,Ā
1,Ā. . . ,Ā![]() t that takes M from the initial state q0 to state p while consuming xa. This
sequence must have a prefix
t that takes M from the initial state q0 to state p while consuming xa. This
sequence must have a prefix ![]() 1,Ā. . . ,Ā
1,Ā. . . ,Ā![]() i that takes M from q0 to some state q while
consuming x (see FigureĀ2.3.4(a)).
i that takes M from q0 to some state q while
consuming x (see FigureĀ2.3.4(a)).
Ā
Ā
![[PICT]](theory-bk-two-2-3-4.jpg)
|
On the other hand, if q is in Ax and if p is a state that is reachable from state q by a
sequence ![]() 1,Ā. . . ,Ā
1,Ā. . . ,Ā![]() s of transition rules that consumes a, then the stateĀp is inĀAxa. In such a
case, if
s of transition rules that consumes a, then the stateĀp is inĀAxa. In such a
case, if ![]() '1,Ā. . . ,Ā
'1,Ā. . . ,Ā![]() 'r is a sequence of transition rules that takes M from the initial
state q0 to state q while consuming x, then M can reach the state p from state q0
by the sequence
'r is a sequence of transition rules that takes M from the initial
state q0 to state q while consuming x, then M can reach the state p from state q0
by the sequence ![]() '1,Ā. . . ,Ā
'1,Ā. . . ,Ā![]() 'r,Ā
'r,Ā![]() 1,Ā. . . ,Ā
1,Ā. . . ,Ā![]() s of transition rules that consumes xa (see
FigureĀ2.3.4(b)).
s of transition rules that consumes xa (see
FigureĀ2.3.4(b)).
As a result, to determine if a1 ![]()
![]()
![]() an is accepted by M, one needs only to follow the
sequence A
an is accepted by M, one needs only to follow the
sequence A![]() , Aa1, Aa1a2,Ā. . . ,ĀAa1
, Aa1, Aa1a2,Ā. . . ,ĀAa1![]()
![]()
![]() an of sets of states, where each Aa1
an of sets of states, where each Aa1![]()
![]()
![]() ai+1 is
uniquely determined from Aa1
ai+1 is
uniquely determined from Aa1![]()
![]()
![]() ai and ai+1. Therefore, a deterministic finite-state
automaton M' of the following form decides the language that is accepted by
M.
ai and ai+1. Therefore, a deterministic finite-state
automaton M' of the following form decides the language that is accepted by
M.
The set of states of M' is equal to { A | A is a subset of Q, and A = Ax for some x in
![]() * }. Since Q is finite, it follows that Q has only a finite number of subsets A, and
consequently M' has also only a finite number of states. The initial state of M' is the
subset of Q that is equal to A
* }. Since Q is finite, it follows that Q has only a finite number of subsets A, and
consequently M' has also only a finite number of states. The initial state of M' is the
subset of Q that is equal to A![]() . The accepting states of M' are those states of M' that
contain at least one accepting state of M. The transition table of M' is the set
{ (A, a, A') | A and A' are states of M', a is in
. The accepting states of M' are those states of M' that
contain at least one accepting state of M. The transition table of M' is the set
{ (A, a, A') | A and A' are states of M', a is in ![]() , and A' is the set of states that the
finite-state automaton M can reach by consuming a from those states that are in
A }.
, and A' is the set of states that the
finite-state automaton M can reach by consuming a from those states that are in
A }.
By definition, M' has no ![]() transition rules. Moreover, M' is deterministic because, for
each x in
transition rules. Moreover, M' is deterministic because, for
each x in ![]() * and each a in
* and each a in ![]() , the set Axa is uniquely defined from the set Ax and the
symbol a.
, the set Axa is uniquely defined from the set Ax and the
symbol a. ![]()
ExampleĀ2.3.3 ĀĀ Let M be the finite-state automaton whose transition diagram is given in FigureĀ2.3.2. The transition diagram in FigureĀ2.3.5
Ā
Ā
![[PICT]](theory-bk-two-2-3-5.jpg)
|
A![]() is the set of all the states that M can reach without reading any input.
q0 is in A
is the set of all the states that M can reach without reading any input.
q0 is in A![]() because it is the initial state of M. q1 and q2 are in A
because it is the initial state of M. q1 and q2 are in A![]() because M
has
because M
has ![]() transition rules that leave the initial state q0 and enter states q1 and q2,
respectively.
transition rules that leave the initial state q0 and enter states q1 and q2,
respectively.
A0 is the set of all the states that M can reach just by reading 0 from those states that
are in A![]() . q0 is in A0 because q0 is in A
. q0 is in A0 because q0 is in A![]() and M has the transition rule (q0, 0, q0). q1 is in
A0 because q0 is in A
and M has the transition rule (q0, 0, q0). q1 is in
A0 because q0 is in A![]() and M can use the pair (q0, 0, q0) and (q0,
and M can use the pair (q0, 0, q0) and (q0, ![]() , q1) of transition rules
to reach q1 from q0 just by reading 0. q2 is in A0 because q0 is in A
, q1) of transition rules
to reach q1 from q0 just by reading 0. q2 is in A0 because q0 is in A![]() and M can use the
pair (q0,
and M can use the
pair (q0, ![]() , q1) and (q1, 0, q2) of transition rules to reach q2 from q0 just by reading 0.
, q1) and (q1, 0, q2) of transition rules to reach q2 from q0 just by reading 0. ![]()
The result of the last theorem cannot be generalized to finite-state transducers,
because deterministic finite-state transducers can only compute functions, whereas
nondeterministic finite-state transducers can also compute relations which are not
functions, for example, the relation {(a, b), (a, c)}. In fact, there are also functions that can
be computed by nondeterministic finite-state transducers but that cannot be computed by
deterministic finite-state transducers. RĀ=Ā{ (x0, 0|x|) | x is a string in {0, 1}* }Ā![]() { (x1, 1|x|) | x is a string in {0, 1}* } is an example of such a function. The
function cannot be computed by a deterministic finite-state transducer because
each deterministic finite-state transducer M satisfies the following condition,
which is not shared by the function: if x1 is a prefix of x2 and M accepts x1 and
x2, then the output of M on input x1 is a prefix of the output of M on input x2
(ExerciseĀ2.2.5).
{ (x1, 1|x|) | x is a string in {0, 1}* } is an example of such a function. The
function cannot be computed by a deterministic finite-state transducer because
each deterministic finite-state transducer M satisfies the following condition,
which is not shared by the function: if x1 is a prefix of x2 and M accepts x1 and
x2, then the output of M on input x1 is a prefix of the output of M on input x2
(ExerciseĀ2.2.5).
ĀFinite-State Automata and Type 3 Grammars
The following two results imply that a language is accepted by a finite-state automaton if and only if it is a Type 3 language. The proof of the first result shows how Type 3 grammars can simulate the computations of finite-state automata.
TheoremĀ2.3.2 ĀĀ Finite-state automata accept only Type 3 languages.
ProofĀ ĀĀ
Consider any finite-state automaton M = <Q, ![]() ,
, ![]() , q0, F>. By TheoremĀ2.3.1 it can be
assumed that M is an
, q0, F>. By TheoremĀ2.3.1 it can be
assumed that M is an ![]() -free, finite-state automaton. With no loss of generality, it can also
be assumed that no transition rule takes M to its initial state when that state is
an accepting one. (If such is not the case, then one can add a new state q'0 to
Q, make the new state q'0 both an initial and an accepting state, and add a new
transition rule (q'0,
-free, finite-state automaton. With no loss of generality, it can also
be assumed that no transition rule takes M to its initial state when that state is
an accepting one. (If such is not the case, then one can add a new state q'0 to
Q, make the new state q'0 both an initial and an accepting state, and add a new
transition rule (q'0, ![]() , q) to
, q) to ![]() for each transition rule of the form (q0,
for each transition rule of the form (q0, ![]() , q) that is in
, q) that is in
![]() .)
.)
Let G = <N, ![]() , P, [q0]> be a Type 3 grammar, where N has a nonterminal symbol
[q] for each state q in Q and P has the following production rules.
, P, [q0]> be a Type 3 grammar, where N has a nonterminal symbol
[q] for each state q in Q and P has the following production rules.
By induction on n it follows that a string a1a2 ![]()
![]()
![]() an has a derivation in G of the
form [q]
an has a derivation in G of the
form [q] ![]() a1[q1]
a1[q1] ![]() a1a2[q2]
a1a2[q2] ![]()
![]()
![]()
![]()
![]() a1a2
a1a2 ![]()
![]()
![]() an-1[qn-1]
an-1[qn-1] ![]() a1a2
a1a2 ![]()
![]()
![]() an
if and only if M has a sequence of moves of the form
qa1a2
an
if and only if M has a sequence of moves of the form
qa1a2 ![]()
![]()
![]() an
an ![]() a1q1a2
a1q1a2 ![]()
![]()
![]() an
an ![]() a1a2q2a3
a1a2q2a3 ![]()
![]()
![]() an
an ![]()
![]()
![]()
![]()
![]() a1
a1 ![]()
![]()
![]() an-1qn-1an
an-1qn-1an ![]() a1a2
a1a2 ![]()
![]()
![]() anqn
for some accepting state qn. In particular the correspondence above holds for q = q0.
Therefore L(G) = L(M).
anqn
for some accepting state qn. In particular the correspondence above holds for q = q0.
Therefore L(G) = L(M). ![]()
ExampleĀ2.3.4 ĀĀ The finite-state automaton M1, whose transition diagram is given in FigureĀ2.3.6(b),
Ā
Ā
![[PICT]](theory-bk-two-2-3-6.jpg)
|
M1 is equivalent to the finite-state automaton M2, whose transition diagram is given
in FigureĀ2.3.6(a). The Type 3 grammar G = <N, ![]() , P, [q'0]> generates the language
L(M2), if N = {[q'0], [q0], [q1], [q2]},
, P, [q'0]> generates the language
L(M2), if N = {[q'0], [q0], [q1], [q2]}, ![]() = {a, b}, and P consists of the following
production rules.
= {a, b}, and P consists of the following
production rules.
The accepting computation q'0abaa ![]() aq1baa
aq1baa ![]() abq0aa
abq0aa ![]() abaq1a
abaq1a ![]() abaaq2 of M2
on input abaa is simulated by the derivation [q'0]
abaaq2 of M2
on input abaa is simulated by the derivation [q'0] ![]() a[q1]
a[q1] ![]() ab[q0]
ab[q0] ![]() aba[q1]
aba[q1] ![]() abaa of
the grammar.
abaa of
the grammar.
The production rule [q1] ![]() a[q2] can be eliminated from the grammar without
affecting the generated language.
a[q2] can be eliminated from the grammar without
affecting the generated language. ![]()
The next theorem shows that the converse of TheoremĀ2.3.2 also holds. The proof shows how finite-state automata can trace the derivations of Type 3 grammars.
TheoremĀ2.3.3 ĀĀ Each Type 3 language is accepted by a finite-state automaton.
ProofĀ ĀĀ
Consider any Type 3 grammar G = <N, ![]() , P, S>. The finite-state automaton
M = <Q,
, P, S>. The finite-state automaton
M = <Q, ![]() ,
, ![]() , qS, F> accepts the language that G generates if Q,
, qS, F> accepts the language that G generates if Q, ![]() , qS, and F are as
defined below.
, qS, and F are as
defined below.
M has a state qA in Q for each nonterminal symbol A in N. In addition, Q also has a distinguished state named qf. The state qS of M, which corresponds to the start symbol S, is designated as the initial state of M. The state qf of M is designated to be the only accepting state of M, that is, F = {qf}.
M has a transition rule in ![]() if and only if the transition rule corresponds to a
production rule of G. Each transition rule of the form (qA, a, qB) in
if and only if the transition rule corresponds to a
production rule of G. Each transition rule of the form (qA, a, qB) in ![]() corresponds to a
production rule of the form A
corresponds to a
production rule of the form A ![]() aB in G. Each transition rule of the form (qA, a, qf) in
aB in G. Each transition rule of the form (qA, a, qf) in ![]() corresponds to a production rule of the form A
corresponds to a production rule of the form A ![]() a in G. Each transition rule of
the form (qS,
a in G. Each transition rule of
the form (qS, ![]() , qf) in
, qf) in ![]() corresponds to a production rule of the form S
corresponds to a production rule of the form S ![]()
![]() in
G.
in
G.
The finite-state automaton M is constructed so as to trace the derivations of the grammar G in its computations. M uses its states to keep track of the nonterminal symbols in use in the sentential forms of G. M uses its transition rules to consume the input symbols that G generates in the direct derivations that use the corresponding production rules.
By induction on n, the constructed finite-state automaton M has a sequence
qA0x ![]() u1qA1v1
u1qA1v1 ![]() u2qA2v2
u2qA2v2 ![]()
![]()
![]()
![]()
![]() un-1qAn-1vn-1
un-1qAn-1vn-1 ![]() xqAn of n moves
if and only if the grammar G has a derivation of length n of the form
A0
xqAn of n moves
if and only if the grammar G has a derivation of length n of the form
A0 ![]() u1A1
u1A1 ![]() u2A2
u2A2 ![]()
![]()
![]()
![]()
![]() un-1An-1
un-1An-1 ![]() x. In particular, such correspondence
holds for A0 = S. Consequently, x is in L(M) if and only if it is in L(G).
x. In particular, such correspondence
holds for A0 = S. Consequently, x is in L(M) if and only if it is in L(G). ![]()
ExampleĀ2.3.5 ĀĀ Consider the Type 3 grammar G = <{S, A, B}, {a, b}, P, S>, where P consists of the following transition rules.
The transition diagram in FigureĀ2.3.7
Ā
Ā
![[PICT]](theory-bk-two-2-3-7.jpg)
|
It turns out that finite-state automata and Type 3 grammars are quite similar mathematical systems. The states in the automata play a role similar to the nonterminal symbols in the grammars, and the transition rules in the automata play a role similar to the production rules in the grammars.
ĀType 3 Grammars and Regular Grammars
Type 3 grammars seem to be minimal in the sense that placing further meaningful restrictions on them results in grammars that cannot generate all the Type 3 languages. On the other hand, some of the restrictions placed on Type 3 grammars can be relaxed without increasing the class of languages that they can generate.
Specifically, a grammar G = <N, ![]() , P, S> is said to be a right-linear grammar if
each of its production rules is either of the form A
, P, S> is said to be a right-linear grammar if
each of its production rules is either of the form A ![]() xB or of the form A
xB or of the form A ![]() x, where A
and B are nonterminal symbols in N and x is a string of terminal symbols in
x, where A
and B are nonterminal symbols in N and x is a string of terminal symbols in
![]() *.
*.
The grammar is said to be a left-linear grammar if each of its production rules is either
of the form A ![]() Bx or of the form A
Bx or of the form A ![]() x, where A and B are nonterminal symbols in N
and x is a string of terminal symbols in
x, where A and B are nonterminal symbols in N
and x is a string of terminal symbols in ![]() *.
*.
The grammar is said to be a regular grammar if it is either a right-linear grammar or a left-linear grammar. A language is said to be a regular language if it is generated by a regular grammar.
By ExerciseĀ2.3.5 a language is a Type 3 language if and only if it is regular.
ĀRegular Languages and Regular Expressions
Regular languages can also be defined, from the empty set and from some finite
number of singleton sets, by the operations of union, composition, and Kleene closure.
Specifically, consider any alphabet ![]() . Then a regular set over
. Then a regular set over ![]() is defined in the following
way.
is defined in the following
way.
TheoremĀ2.3.4 ĀĀ A set is a regular set if and only if it is accepted by a finite-state automaton.
Regular sets of the form ž, {![]() }, {a}, L
}, {a}, L![]()
![]() L
L![]() , L
, L![]() L
L![]() , and L
, and L![]() * are quite often denoted
by the expressions ž,
* are quite often denoted
by the expressions ž, ![]() , a, (
, a, (![]() ) + (
) + (![]() ), (
), (![]() )(
)(![]() ), and (
), and (![]() )*, respectively.
)*, respectively. ![]() and
and ![]() are assumed
to be the expressions that denote L
are assumed
to be the expressions that denote L![]() and L
and L![]() in a similar manner, respectively. a is
assumed to be a symbol from the alphabet. Expressions that denote regular sets in this
manner are called regular expressions.
in a similar manner, respectively. a is
assumed to be a symbol from the alphabet. Expressions that denote regular sets in this
manner are called regular expressions.
Some parentheses can be omitted from regular expressions, if a precedence relation between the operations of Kleene closure, composition, and union in the given order is assumed. The omission of parentheses in regular expressions is similar to that in arithmetic expressions, where closure, composition, and union in regular expressions play a role similar to exponentiation, multiplication, and addition in arithmetic expressions.
ExampleĀ2.3.6 ĀĀ
The regular expression 0*(1*01*00*(11*01*00*)* + 0*10*11*(00*10*11*)*) denotes
the language that is recognized by the finite-state automaton whose transition diagram is
given in FigureĀ2.3.2. The expression indicates that each string starts with an arbitrary
number of 0's. Then the string continues with a string in 1*01*00*(11*01*00*)* or with
a string in 10*11*(00*10*11*)*. In the first case, the string continues with an arbitrary
number of 1's, followed by 0, followed by an arbitrary number of 1's, followed by one
or more 0's, followed by an arbitrary number of strings in 11*01*00*. ![]()
By the previous discussion, nondeterministic finite-state automata, deterministic finite-state automata, regular grammars, and regular expressions are all characterizations of the languages that finite-memory programs accept. Moreover, there are effective procedures for moving between the different characterizations. These procedures provide the foundation for many systems that produce finite-memory-based programs from characterizations of the previous nature. For instance, one of the best known systems, called LEX , gets inputs that are generalizations of regular expressions and provides outputs that are scanners. The advantage of such systems is obviously in the reduced effort they require for obtaining the desired programs.
FigureĀ2.3.8
Ā
Ā
![[PICT]](theory-bk-two-2-3-8.jpg)
|
!['
[q0] --> e
--> a[q1]
--> b[q1]
[q0] --> a[q1]
--> b[q1]
[q1] --> b[q0]
--> b
--> a[q2]
--> a](theory-bk-two11x.gif)